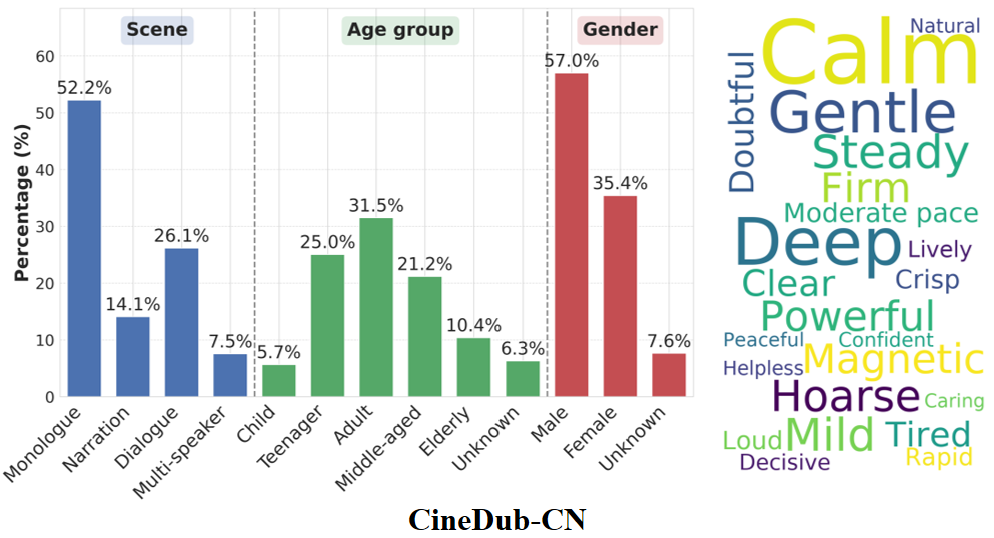
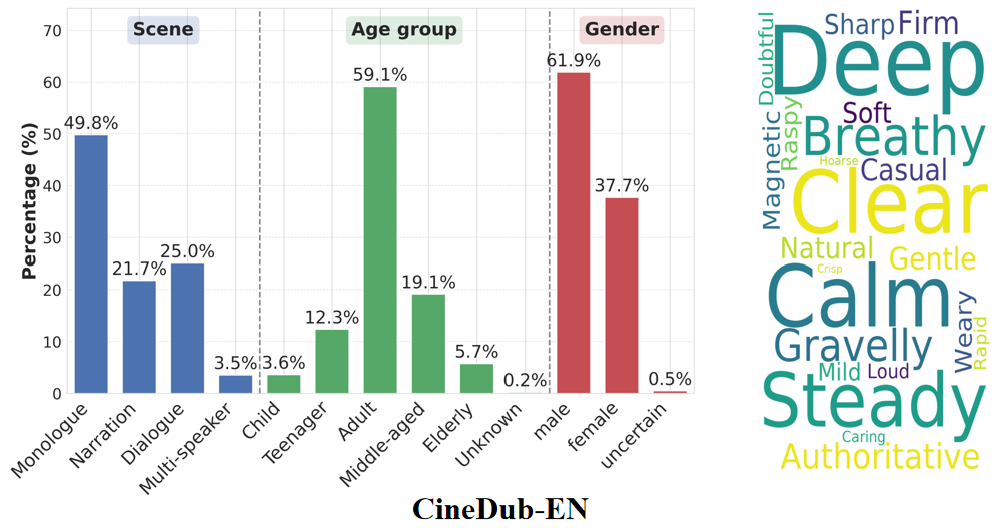
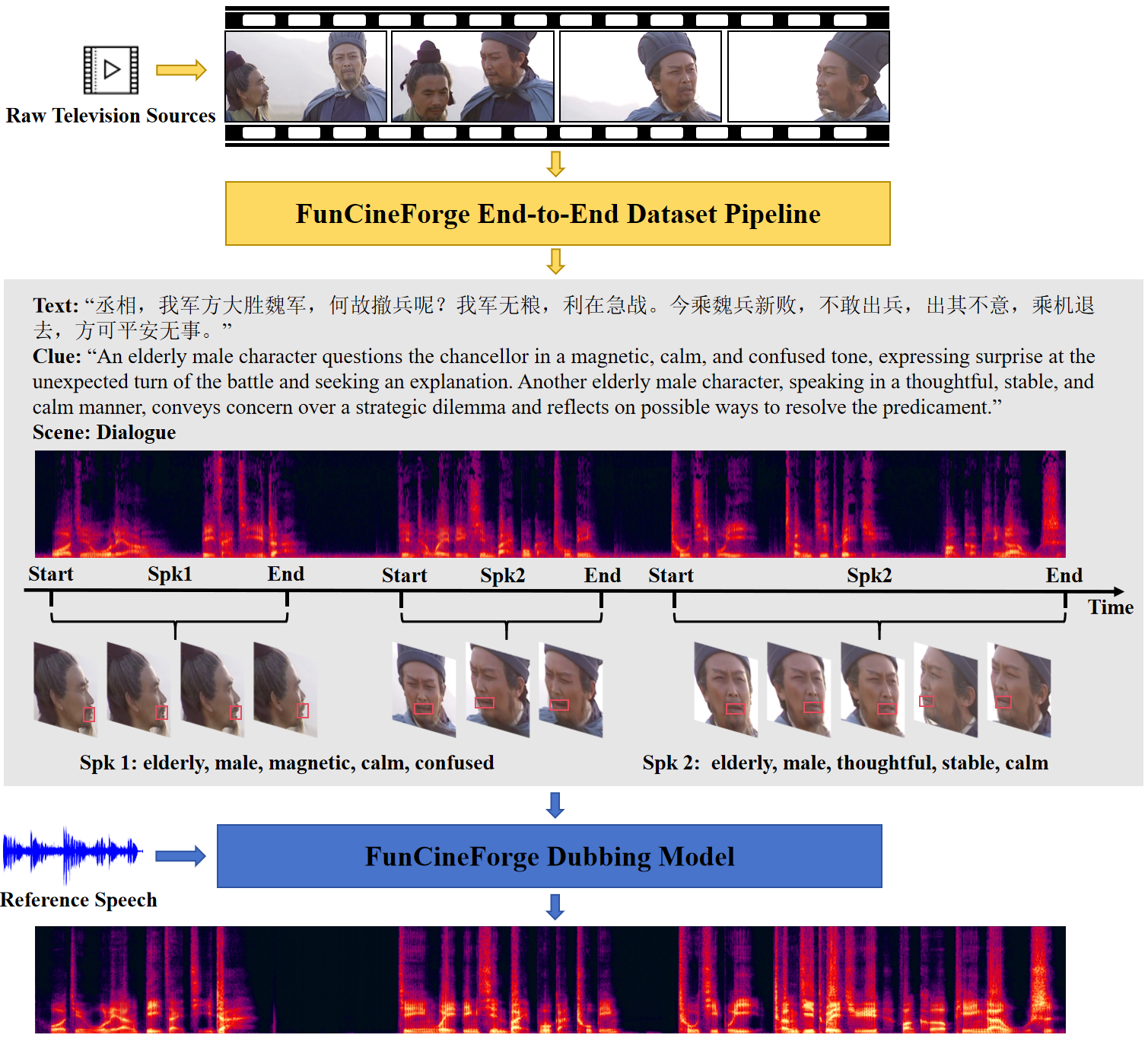
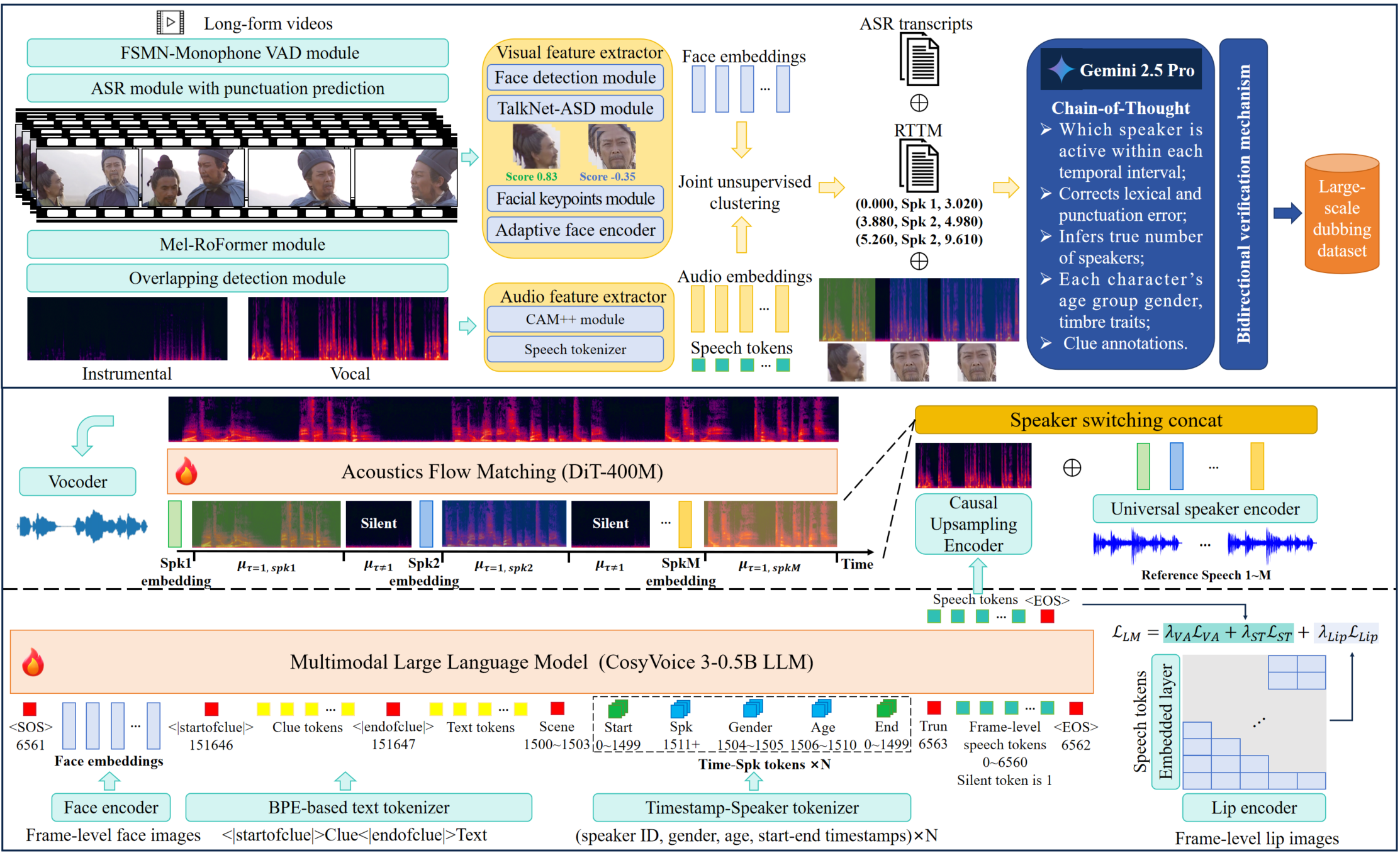
Type:
monologue (emotional)
Clue + Text:
“<|startofclue|>一位中年男性角色,语气低沉生气,带着明显的无奈。表达了他自己一无所知、无法发言的困境,流露出深刻的无助与自我贬低的情绪。<|endofclue|>
我没有说什么,我现在什么都不知道了,我一只火鸡我能说什么呢?”
Clue + Text (Translation):
"<|startofclue|>A middle-aged male character, speaking in a low and angry tone, with evident helplessness.
He expresses his dilemma of knowing nothing and being unable to speak, revealing a profound sense of helplessness and self-deprecation.<|endofclue|>
I didn't say anything. I don't know anything now. I'm just a turkey, what can I say?"
Type:
monologue (shot change)
Clue + Text:
“<|startofclue|>一位中年男性角色向大王陈述立场,语气沉稳且坚定,言辞间流露出对自身忠诚的强烈自信与决心。整体情感线索是忠贞不渝的承诺和不容置疑的信念。<|endofclue|>
大王若是圣明,自然知道我张仪就是掉了脑袋,也不会把秦国的土地轻易交给楚国。”
Clue + Text (Translation):
"<|startofclue|>A middle-aged male character states his position to the king, with a calm and firm tone, revealing a strong confidence and determination in his loyalty.
The overall emotional thread is an unwavering commitment and unquestionable belief.<|endofclue|>
If the king is wise, he naturally knows that even if I, Zhang Yi, lose my head, I will not easily surrender the land of Qin to the state of Chu."
Type:
monologue (shot change)
Clue + Text:
“<|startofclue|>一位中年女性以沉稳语重心长的语气表达了对女儿未来的担忧和长远规划的考虑,劝诫不要为一时意气而牺牲未来,情感是理性而富有责任感,带有微弱的忧虑。<|endofclue|>
若换作是我的闺女,我会替她的后半辈子做打算,而不是争一时意气。”
Clue + Text (Translation):
"<|startofclue|>A middle-aged woman expressed her concerns about her daughter's future and considerations for long-term planning in a calm and earnest tone,
advising against sacrificing the future for a momentary impulse. Her emotions were rational and responsible, tinged with a slight sense of anxiety.<|endofclue|>
If it were my daughter, I would plan for her future, rather than acting on a whim."
Type:
monologue (shot change)
Clue + Text:
“<|startofclue|>一位青年男性角色以沉稳冷静的语气发表评判性言论,表达了对某人证词可信度的质疑和不信任。<|endofclue|>
此人与令如兰关系甚密,他的证词恐怕不足为信。”
Clue + Text (Translation):
"<|startofclue|>A young male character delivers critical remarks in a calm and composed tone,
expressing doubts and mistrust towards the credibility of someone's testimony.<|endofclue|>
This person is closely related to Ling Rulan, so his testimony may not be credible."
Type:
monologue (frequent shot changes)
Clue + Text:
“<|startofclue|>一位男性臣子附和华妃的观点,强调与皇帝共同用餐的珍贵,语气沉稳而得体。<|endofclue|>
华妃说得对啊,臣难得与皇上一桌用餐,一家子团聚是不该议论其他!”
Clue + Text (Translation):
"<|startofclue|>A male courtier echoed the view of Consort Hua, emphasizing the preciousness of dining with the emperor, speaking in a calm and appropriate tone.<|endofclue|>
Consort Hua is right. It's rare for courtiers to dine with the emperor at the same table. When the family gathers, we shouldn't discuss other matters!"
Type:
monologue (far shot)
Clue + Text:
“<|startofclue|>一位青年女性语气紧张且略带委屈。她解释因害怕牵连大人而胡言乱语,随后疑惑地询问自己是否说错了,情绪从焦虑到疑惑。<|endofclue|>
刺客问我,我不敢不答,又怕牵连大人让您为难,所以只能乱说了。怎么,是雪宁说错了吗?”
Clue + Text (Translation):
"<|startofclue|>A young woman spoke in a tense tone, slightly aggrieved. She explained that she had been speaking incoherently for fear of implicating adults, and then asked doubtfully if she had said something wrong,
her emotions shifting from anxiety to confusion.<|endofclue|>
The assassin asked me, and I didn't dare not answer, but I was also afraid of implicating adults and causing you embarrassment, so I could only speak incoherently. What, did Xue Ning say something wrong?"
Type:
monologue (dark face)
Clue + Text:
“<|startofclue|>一位中年男性以沉稳有力的语调,阐述了他对事物的判断哲学,从不知道到明确提出自己的定理,语气坚定,透露出一种笃信和深思熟虑的意味。<|endofclue|>
我虽然不知道你说的那个什么假说,但是我知道,我知道一个终极定理。那就是:邪乎到家必有鬼!”
Clue + Text (Translation):
"<|startofclue|>A middle-aged man expounded on his philosophy of judgment towards things with a steady and powerful tone, moving from not knowing to explicitly proposing his own theorems.
His tone was firm, revealing a sense of conviction and deep consideration.<|endofclue|>
Although I don't know about the hypothesis you mentioned, I do know one ultimate theorem. That is: Where there's something fishy, there must be a ghost!"
Type:
monologue (dark environment)
Clue + Text:
“<|startofclue|>一位青年男性,语气中充满对已逝亲人的深切怀念与对过去美好生活的向往,语调柔和,略带感伤。<|endofclue|>
若是你和阿爹还在的话,我们就可以像小时候那样一起生活了。”
Clue + Text (Translation):
"<|startofclue|>A young man, his tone filled with deep nostalgia for his deceased loved ones and longing for the good old days, spoke softly, slightly tinged with sadness.<|endofclue|>
If you and Dad were still here, we could live together like we did when we were young."
Type:
monologue (children)
Clue + Text:
“<|startofclue|>一个小女孩用悲伤、柔和但坚定的语气表达了对哥哥的深切关爱。她暗示自己处境艰难,却希望哥哥能好好活着,充满自我牺牲的爱。<|endofclue|>
哥哥,因为你带我很难活下来,我想让哥哥活下去,好好地活着”
Clue + Text (Translation):
"<|startofclue|>A little girl expressed her deep care for her brother in a sad, gentle yet firm tone. She hinted at her difficult situation, yet hoped that her brother could live well, filled with self-sacrificing love.<|endofclue|>
Brother, because you make it hard for me to survive, I want you to live on, to live well."
Type:
monologue (elderly)
Clue + Text:
“<|startofclue|>一位老年男性角色回顾往事,语调沉稳,略带一丝无奈和叹息。描述某人曾效力一方后又放弃的经历。<|endofclue|>
许多年前,他曾经站在琅琊王那边,可是他自己放弃了。”
Clue + Text (Translation):
"<|startofclue|>An elderly male character reflects on the past, speaking in a steady tone, tinged with a hint of helplessness and sighing. Describing someone who once served a faction but later gave up.<|endofclue|>
Many years ago, he once stood by the side of the Prince of Langya, but he himself gave up."
Type:
monologue (crowd shot)
Clue + Text:
“<|startofclue|>一位男性领导在进行正式讲话,语调沉稳有力,旨在强调听众肩负的重要职责,整体情感庄重而富有号召力。<|endofclue|>
在座的各位,你们都肩负着光明县经济、社会持续健康发展重任。”
Clue + Text (Translation):
"<|startofclue|>A male leader is giving a formal speech with a steady and powerful tone, aiming to emphasize the important responsibilities borne by the audience.
The overall emotion is solemn and powerful.<|endofclue|>
Ladies and gentlemen, you all shoulder the important task of ensuring the sustained and healthy development of Guangming County's economy and society."